


El funcionamiento del aprendizaje automático
En los ejemplos de Aprendizaje Automático anteriores, lo único que solemos ver son los resultados.
Rara vez podemos asistir al complejo proceso necesario para encontrar un nuevo agujero negro y tampoco pensamos en el número de permutaciones de eventos los meteorológicos del pasado que son necesarios para prever el tiempo que hará hoy.
Con frecuencia, en estas tareas se emplean conjuntos enormes de datos, muchos algoritmos y una potencia computacional importante. Si nos pusiéramos a analizar a fondo las distintas categorías de aprendizaje automático (algo que no vamos a hacer en esta serie), veríamos que cada una de ellas (aprendizaje supervisado, no supervisado, semisupervisado y por refuerzo) se emplea para cumplir unas tareas específicas.
Uno de los componentes más importantes de cualquier aplicación de AA es la red neuronal. En términos generales, una red neuronal viene a ser un intento de replicar la función de las neuronas humanas en un modelo matemático. El modelo TinyML utiliza algoritmos para inferir las probabilidades de un resultado (por ejemplo, en el reconocimiento de imágenes o que la probabilidad de que una imagen determinada sea un perro es del 95 %). Hay diferentes tipos de redes neuronales y verás conceptos como las redes neuronales convolucionales (CNN) o recurrentes (RNN). Cada tipo de red neuronal tiene un conjunto distinto de capas interconectadas a fin de adaptarse a tareas específicas.
El aprendizaje supervisado consiste en instruir a una red con una gran cantidad de datos de formación para que un algoritmo pueda inferir un resultado. Por ejemplo, en el reconocimiento de imágenes, la mejor opción es una CNN. Para identificar distintos tipos de fruta, debemos darle al algoritmo de la red neuronal miles de fotos etiquetadas con distintas frutas, desde diferentes ángulos y con varios grados de maduración. A partir de aquí, el algoritmo TinyML buscará características que le permitan distinguir las frutas. La fase de formación es iterativa, y es posible que haya que retocar el algoritmo para tener más probabilidades de éxito al analizar un conjunto de imágenes de ensayo.
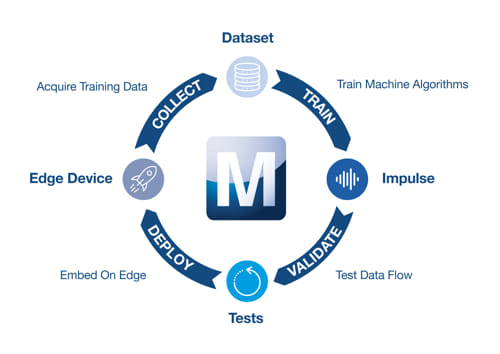
Cuando los datos de ensayo obtienen el mejor rendimiento posible en al algoritmo de la red neuronal, el modelo ya se puede implantar. Durante este paso, llamado también inferencia, el modelo deduce los resultados basándose en las probabilidades.
Cuando hablamos con un altavoz inteligente, normalmente utilizamos una frase para activarlo (por ejemplo, «Hola, Google»), de modo que el dispositivo esté atento a lo que digamos después. Un altavoz inteligente no tiene la capacidad computacional de un centro de datos, así que se registran archivos de audio cortos y se envían a la nube para determinar qué es lo que estamos pidiendo. La detección de esta frase inicial es un ejemplo fantástico del aprendizaje automático simple o TinyML.









{kind=link}