


¿Cómo se “entrena” una máquina?
El primer paso es la recopilación de datos.
A medida que nos enfocamos en el aprendizaje supervisado, recopilamos datos etiquetados para que los patrones se puedan encontrar correctamente. La calidad de estos datos determinará la precisión del modelo.
Necesitamos armarlo y hacerlo aleatorio, ya que, si está demasiado organizado, los modelos no se crearán correctamente y podemos terminar con algoritmos defectuosos.
El segundo paso es limpiar y eliminar los datos no deseados. Cualquier conjunto en el que falten algunos futuros debe eliminarse. Cualquier estado en el que no se necesiten los datos o cualquier estado que normalmente se desconozca también debe eliminarse.
Luego, los datos deben separarse en dos partes, una para entrenamiento y otra para prueba.
El tercer paso es entrenar el algoritmo. Esto se divide en tres pasos. El primer paso es elegir el algoritmo de clasificación de aprendizaje automático. Varios están disponibles y son adecuados para diferentes tipos de datos.
Ejemplo de algoritmo de clasificación de aprendizaje automático son:
- Bonsái
- Conjunto de árboles de decisión
- Conjunto de árbol potenciado
- TensorFlow Lite para microcontroladores
- PME
Es importante elegir la composición del modelo correcto, ya que esto determina el resultado que obtiene después de ejecutar el algoritmo ML en los datos recopilados. Esto puede requerir algunas habilidades de científico de datos, pero también podría dejarse en manos del motor automático proporcionado por varias herramientas de creación de modelos.
El segundo subpaso es la operación de entrenamiento del modelo, que consiste en ejecutar varias iteraciones para mejorar los pesos de las diferentes capas y la precisión general del modelo.
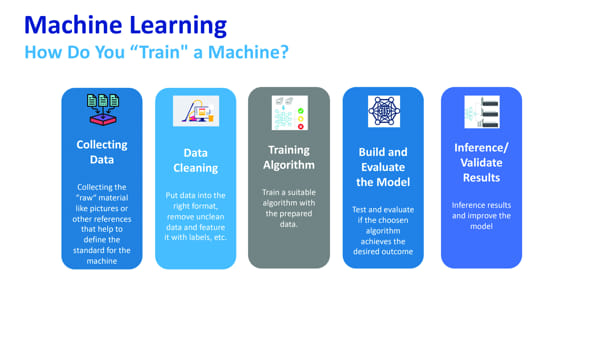
Luego necesitamos evaluar el modelo, lo cual se hace probando el modelo con un subconjunto de datos. El que ya hemos guardado para futuras pruebas y evaluaciones. Este conjunto de datos es desconocido para el modelo. Luego podemos comparar la salida del modelo con los resultados conocidos.
Una vez que hayamos completado estos pasos, podemos usar el modelo creado y validar los resultados realizando inferencias en los objetivos. La idea es llevar el modelo al campo, proporcionarle algunos insumos y ver si los resultados son correctos.









{kind=link}